Addressing Overprovisioning & Performance Issues in Node.js via Multiple Workers

P
Node.js TSC Member, Principal Engineer at Platformatic, Polyglot Developer. RPG and LARP addicted and nerd on lot more. Surrounded by lovely chubby cats.
Search for a command to run...
Node.js TSC Member, Principal Engineer at Platformatic, Polyglot Developer. RPG and LARP addicted and nerd on lot more. Surrounded by lovely chubby cats.
No comments yet. Be the first to comment.
Nitro is a server toolkit used by many JavaScript applications. You can use it on its own for APIs or full-stack servers, or combine it with Vite to get a familiar frontend workflow with a Nitro serve

All durable execution engines give the same versioning advice: pin your runs. Temporal pins runs to worker builds. Vercel's Workflow SDK pins each run to the deployment that started it. Azure Durable

Eve organizes AI agents in a simple way: use Markdown for instructions and skills, TypeScript for tools, and separate files for channels, schedules, and subagents. Behind this setup, Eve relies on the

Picture an online store launching a new product and sending out a mailing list campaign. Thousands of users click the same link at once. The product page, built with a Node.js app like Next.js, needs

How Platformatic ICC Outperforms AWS ECS Target Tracking and Step Scaling

On this page
Scaling Node.js applications efficiently has long been a challenge for teams. Traditionally, Node.js runs on a single thread per service, meaning each instance operates as a single process within its container. This forces teams to overprovision infrastructure to handle unpredictable traffic spikes, leading to wasted resources and increased costs.
The single-threaded nature of Node.js can pose performance risks; if a thread blocks its event loop due to a computationally heavy operation or a sudden traffic spike, it can cause downtime or degrade user experience.
This raises a crucial question:
How can teams optimize Node.js resource utilization to reduce costs without compromising performance or risking downtime?
The answer begins one month ago, when we shipped Platformatic v2. With this version, we introduced support for all the stacks you love the most, including Next.js, Astro, Express, and Fastify.
On the same day, we also launched Watt, the Node.js Application Server, enabling you to run multiple Node.js applications (services) that are centrally managed.
With Watt, services are launched in worker threads whenever possible to minimize overhead; otherwise, additional child processes are spawned to ensure we can support any of your complex applications.
By using Watt, you gain access to a virtual mesh network, fast logging via Pino, monitoring through Prometheus, and OpenTelemetry integration—all at no additional cost.
Today, however, we are taking this solution one step further by introducing multiple workers.
Traditionally, Node.js services have been limited to a single thread per service. This has meant that every Node.js instance operates as a single process within its container. As a result, companies often find themselves over-provisioning resources to deal with traffic spikes or ensuring redundancy, which, in turn, leads to under-utilized resources and inflated infrastructure costs.
The single-threaded nature of Node.js has also presented performance challenges. If a thread blocks its event loop due to a computationally heavy operation or a sudden spike, it can negatively impact the performance of your service.
In an instance where there is only one thread, this event loop blocking can lead to downtime or degraded user experience. Companies are then forced to compensate for this by deploying more instances or overprovisioning even further, creating inefficiencies.
Fundamentally, the current single-threaded system is reactive, not predictive—companies provision for peak loads that may only occur occasionally, wasting resources during stable periods.
What does all this mean? Rising, uncontrolled infra costs, and unreliable service delivery– something we all want to avoid.
When you use Watt today, you can define as many services as you like. Most of the time, these services will execute in worker threads within the same Watt process.
While the number of services can be quite high and theoretically maximize your CPU capability, the reality is that many users do not define as many services, leading to underutilization of the CPU.
Consider a typical scenario where you have a frontend service, an API service, and a database service. At any given time, the maximum number of cores you can utilize is three, which is less than half of the average number of cores found in modern CPUs.
This underutilization can severely impact performance, especially during CPU-intensive tasks. Such tasks can hinder Event Loop Utilization (ELU) by keeping the process busy and preventing it from executing asynchronous operations. In essence, a CPU-intensive operation can block your application from processing other tasks.
A common example is Server-Side Rendering (SSR). When executing SSR, the frontend process becomes fully occupied and cannot accept new requests. A poorly performing SSR system can significantly affect your frontend response times, thereby diminishing the overall browsing experience for your users.
Starting from Watt 2.8.0, we now support service replication. Each service can now spawn multiple instances, known as workers, all running within the same process. Each worker of a service is identical and benefits from all the features that Watt offers.
By starting multiple workers, you can fully utilize all the CPU cores available on your server, providing the best possible user experience. When serving the client request, the runtime will select one of the available workers with a round-robin policy and use it to fulfill the request.
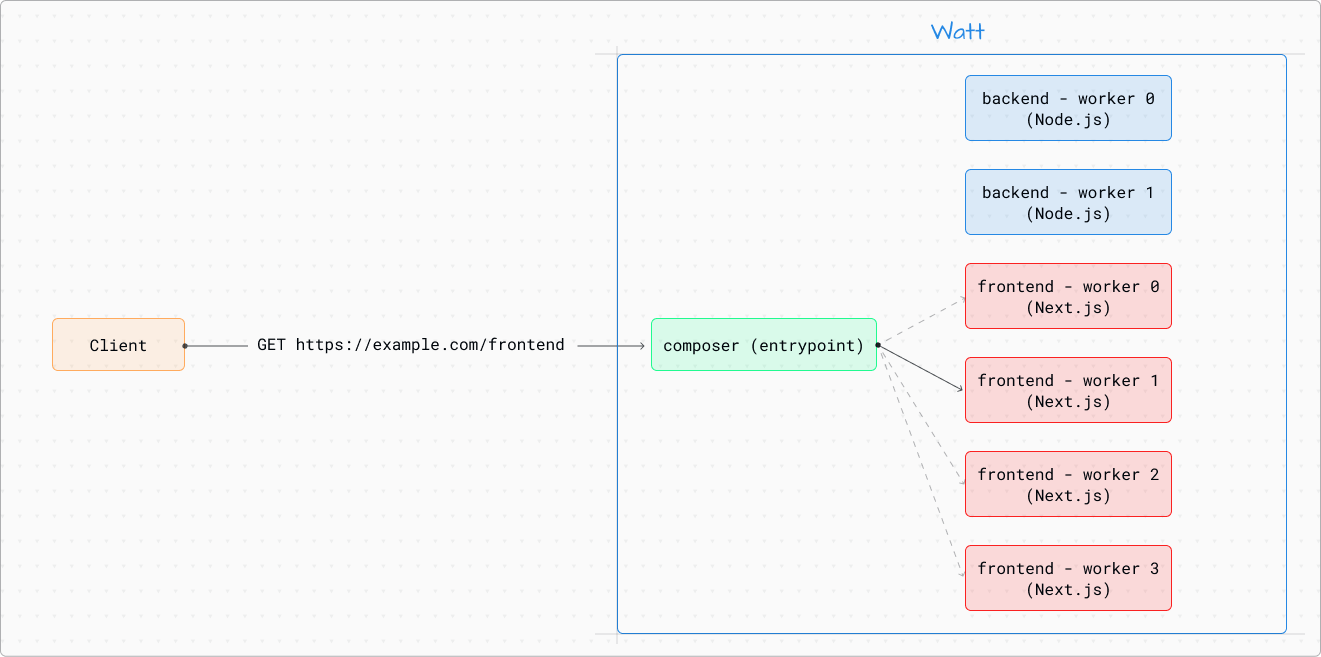
Most importantly, this is all done without requiring any code changes on your part.
You simply modify your watt.json file to include a workers setting at either the service level or the global level, and you’re ready to go!
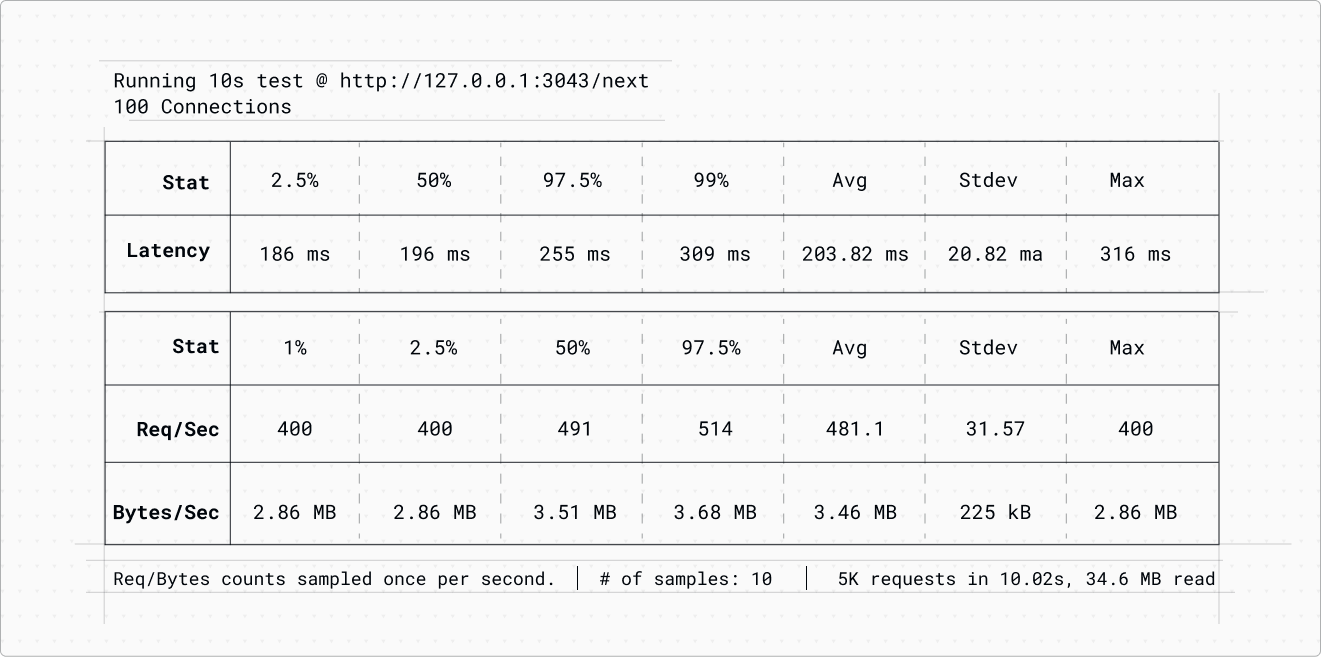
To illustrate the benefits of multiple workers, let’s analyze a basic Next.js application running within Watt. This test was conducted on an Apple MacBook Pro with an M1 Max chip.
When subjected to 100 connections using autocannon over a span of 10 seconds, the system produced the following performance metrics:
Upon examining the top data, we found that only 3 out of the 10 available cores were actually utilized.
We then repeated the test, increasing the number of workers to 2. To achieve that we just set a configuration variable in the main watt.json file:
{
"$schema": "https://schemas.platformatic.dev/@platformatic/runtime/2.0.0-alpha.18.json",
"entrypoint": "composer",
"server": {
"port": 3043
},
"logger": {
"level": "info"
},
"autoload": {
"path": "services"
},
"workers": 2
}
Here are the updated results:
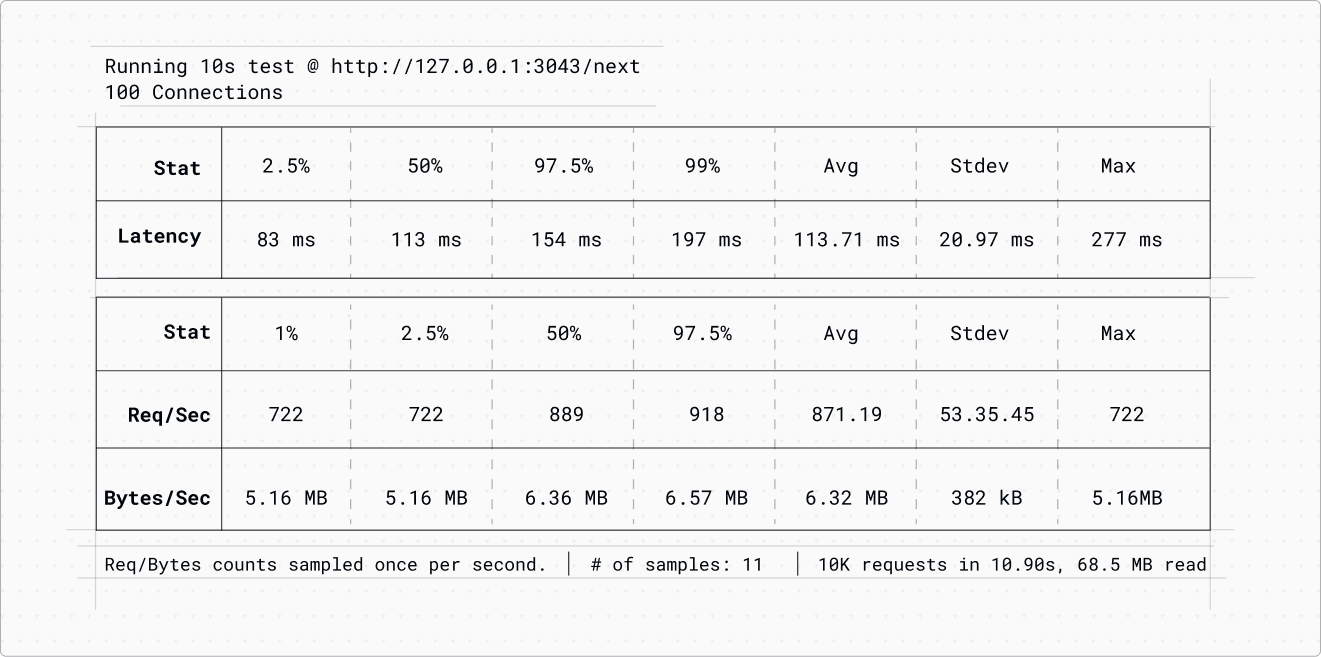
This shows an impressive performance boost—almost a 100% improvement—simply by changing one line in the watt.json file.
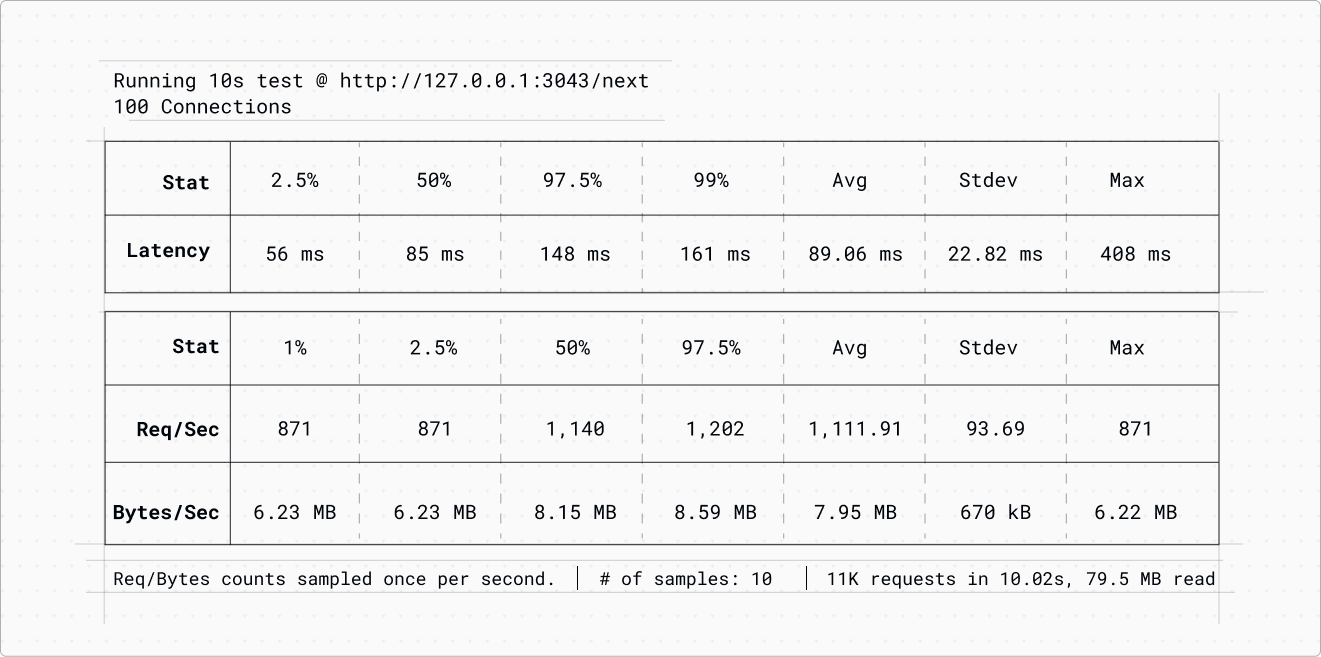
Finally, we repeated the test, this time using 3 workers for the service:
The average number of requests continues to increase linearly.
Upon reviewing the top data once more, we found that all 10 CPU cores of the machine were fully utilized. Mission accomplished!
With the introduction of multiple workers, we're transforming how Node.js services scale and perform, bringing Node.js one step closer to how Java applications handle resource management, enabling a more efficient, multi-threaded architecture while retaining the simplicity and flexibility of Node.js.
The benchmarks we outlined clearly demonstrate how easy it is to achieve significantly better performance by switching to Watt and leveraging multiple workers.
By leveraging Watt, you can easily:
Spin up multiple copies of the same thread: You can now configure how many threads or processes each service should scale with, adding flexibility to dynamically adapt resource allocation based on demand.
Instantiate multiple copies of the same service or frontend application: This allows for better scaling of frontend systems, server-side rendering (SSR), and APIs that require dynamic scaling without incurring the penalties of overprovisioning.
Exhaust resources vertically: Maximize your infrastructure by using all available CPU and memory resources more efficiently within a single deployment unit. Previously, Node.js services were seen as single processes running inside single containers. Now, we enable multiple processes or threads within the same deployment unit, driving organizations to save on infrastructure costs without compromising performance or increasing risk.
What does this mean for you and your team?
Enhanced performance and resilience: If one thread blocks its event loop, other threads can keep running, ensuring your service remains resilient and available even under heavy load or during traffic spikes. Each thread progresses at its own pace, avoiding any buildup of work due to event loop blocking.
Reduced infrastructure costs: By scaling services within a single deployment unit, your organization can save on infrastructure costs without sacrificing performance. Instead of paying for unused resources during stable traffic periods, this functionality ensures you only use what you need when you need it.
Optimize for CPU-bound tasks: Now, you can exhaust CPU and memory resources more efficiently without needing to spin up additional containers or instances, reducing the risk of overprovisioning.